「排他的XML正則化 バージョン 1.0」の版間の差分
(相違点なし)
|
2009年2月10日 (火) 00:09時点における最新版
W3C勧告2002年6月18日
- このバージョン
- http://www.w3.org/TR/2002/REC-xml-exc-c14n-20020718/
- 最新のバージョン
- http://www.w3.org/TR/xml-exc-c14n/
- 以前のバージョン
- http://www.w3.org/TR/2002/PR-xml-exc-c14n-20020524/
- 編者
- John Boyer, PureEdge Solutions Inc., jboyer@PureEdge.com
- Donald E. Eastlake 3rd, Motorola, Donald.Eastlake@Motorola.com
- Joseph Reagle, W3C, reagle@w3.org
この文書に含まれる規定の修正箇所はエラッタを参照されたい。また、翻訳一覧も参考まで。
著作権© 2002 W3C®(マサチューセッツ工科大学、フランス国立情報処理自動化研究所、慶應義塾大学)により、全ての権利が留保される。W3Cの免責、商標、文書利用、ソフトウェア使用許諾規定が適用される。
概要
[編集]正則なXML [XML-C14N] はXMLの標準的な直列化として、ある文書の一部へ適用した場合に、その文書の一部の祖先コンテキストに含まれる全ての名前空間宣言と"xml:"名前空間の属性を含むことを規定する。しかし、あるアプリケーションでは、正則化済みの文書の一部から実用する範囲まで、祖先コンテキストを除外するための方法を求められる。例えば、文書の一部が原本から削除される、および、異なるコンテキストへ挿入される時にも壊れる可能性のないXMLメッセージ中のXMLペイロード(文書の一部)を用いたデジタル署名を、誰もが必要と思うだろう。この要件は、排他的XML正則化によって成される。
この文書の位置づけ
[編集]この文書は、W3Cの排他的正則化勧告である。この文書はW3C会員と他の関係者によって評価済みであり、管理者によりW3C勧告として支持されている。それは完成した文書であり、参照資料として使われたり、他の文書から基準となる参考資料として引用されても良い。勧告作成にかかるW3Cの役割は、仕様書を注目させ、その広範な展開を促進することにある。これによってウェブにおける機能性と相互運用性がより高まる。
この仕様書は、IETF/W3C XMLシグネチャ ワーキンググループ(活動声明)によって発行された。ワーキンググループはこの仕様書が、相互運用性報告書の中で明示されたような共同利用できる実装の作成のために十分だと信じる。
この仕様書に関連する特許開示情報は、W3Cの方針に適合するワーキンググループの特許開示ページ、そしてIETFの方針に適合するIETF知的所有権ページで参照できる。刊行時には、この文書特有の定義はない
この文書の誤りは、w3c-ietf-xmldsig@w3.org(記録)に報告されたい。
この仕様書の既知の誤りは、http://www.w3.org/2002/07/xml-exc-c14n-errataで得られる。
この仕様書の英語版のみが規範となる版である。この文書の翻訳版についての情報は、(もしあるなら)http://www.w3.org/Signature/2002/02/xmldsig-translationsで得られる。
最新のW3C技術報告のリストはhttp://www.w3.org/TR/で参照できる。
導入
[編集]XML勧告[XML]は、XML文書と呼ばれるオブジェクト集合の構文を定める。XML名前空間勧告[XML-NS]は、XML文書のための追加の構文と意味を定める。等価なXML文書とXML文書の一部が、多くのアプリケーションの意図するところのために物理的表現が異なることは普通のことである。例えば、実体構造や属性順番、そして文字符号化が異なってもよい。この仕様書の目的は、以下のように、あるXML文書やその一部のXPathノード集合表現の直列化方法を確立するところにある。すなわち、
- 排除済みXMLコンテキストによるノード集合への影響が少ない
- 安定した(well-balanced)XML[XML-Fragment]を表すノード集合の正則化では、排他的正則化のための新機能を用いてもノード集合は変更されない
- XML勧告[XML]とXML名前空間勧告[XML-NS]に基づくこの仕様書によって重要でないとみなされた変形を除き、二つのノード集合が同一であるかどうかを決定付けることができる
正則なXML勧告[XML-C14N]の理解が求められる。
用語
[編集]この文書において"しなければならない[MUST]"、"してはならない[MUST NOT]"、"要求されている[REQUIRED]"、"することになる[SHALL]"、"することはない[SHALL NOT]"、"する必要がある[SHOULD]"、"しないほうがよい[SHOULD NOT]"、"推奨される[RECOMMENDED]"、"してもよい[MAY]"、"選択できる[OPTIONAL]"といった単語は RFC 2119 [Keywords]に記述されているように解するものとする。
XPath 1.0勧告[XPath]は、ノード集合(node-set)という用語を定義し、様々な型(要素、属性、名前空間、テキスト、注釈、処理命令、ルート)のノードの集まりとして提供されたXML文書を表すデータモデルを規定する。ノードは、ある式の評価に基づいたノード集合から排除されるか、あるいは含まれる。この仕様書と正則なXML勧告[XML-C14N]においてノード集合とは、それぞれのノードが正則正式の中に出現するべきかどうかを直接的に示すものである(ここでは、純粋に数学的な集合の意である)。たとえその親ノードがノード集合に含まれようとも、集合から排除されたあるノードは正則形式に出現しない。しかし、排除されたノードはなおもその子孫のあらましに影響を与えるかもしれない(例えば、子孫の名前空間コンテキストに作用することにより)。
文書部分集合(document subset)とは、文書内の全てのノードを含まないかもしれないXPathノード集合で示されるXML文書の一部分である。XPath[XPath]で定義されているように、どんなノード(例えば要素、属性、名前空間)も必ず要素ノードかルートノードのどちらかである親(parent)を持つ。頂点ノード(apex node)とは、文書部分集合中の祖先に親ノードを持たない要素である。孤児ノード(orphan node)とは、文書部分集合内に親要素ノードが存在しない要素ノードである。頂点ノードではない孤児ノードの出力された親(output parent)とは、文書部分集合中に存在するその孤児ノードに最も近い祖先要素である。頂点ノードは出力された親を持たない。孤児ノードではないノードの出力された親は、ノードの親と同じである。出力された祖先(output ancestor)とは、文書部分集合内のあらゆる祖先要素ノードである。
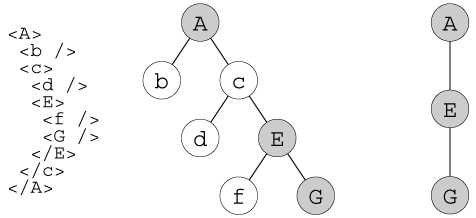
例えば、ルートノードAの下に3世代を伴う文書ツリーが与えられ、そこに大文字で表されたノード(A、E、G)が文書部分集合内に存在する。
画像の説明、
文字での説明、
A-+-b
`-c-+-d
`-E-+-f
`-G
次のような特徴が当てはまる。すなわち、
- Aは頂点ノードで、Eの出力された親で、EとGの出力された祖先である
- Eは孤児ノードで、Gの出力された親である
E、あるいはEを親としてもつ文書部分集合中のある属性ノードが、名前空間接頭辞Pによって修飾された名前を持つ場合、文書部分集合内の要素Eは名前空間宣言、すなわち名前空間接頭辞Pと結合した値Vを有形利用(visibly utilizes)する。同様の定義として、文書部分集合中の要素Eは、Eが名前空間接頭辞を持たない場合、存在する既定名前空間宣言を有形利用する。
あらゆる非既定名前空間宣言をノードに含むある要素のancestor軸は、要素の祖先から継承した非既定名前空間宣言と同様、要素の内部に作成される。既定名前空間が要素内部や要素の祖先で宣言済みであっても空値でないならば、namespace軸もまた既定名前空間を示すノードを含む。namespace軸中のノードのどんな部分集合であっても、文書部分集合に含まれる可能性がある。
この仕様書が記す正則化方法では、ある包括的名前空間接頭辞一覧(InclusiveNamespaces PrefixList)値を受け入れる。包括的名前空間接頭辞一覧とは、正則なXML勧告[XML-C14N]に記載されたやり方で取り扱われる名前空間接頭辞を一覧するものである。
文書部分集合の排他的正則形式(exclusive canonical form)とは、この仕様書に記載する方法によってもたらされた、連続したデータとしてのXPathノード集合の物理的表現である。排他的正則形式は後述する変更点を除き、正則なXML勧告[XML-C14N]で定義されたものと同じである。すなわち、
- xml:langやxml:spaceのようなXML名前空間の属性は、文書部分集合内の孤児ノードの中へ取り込まれない
- 包括的名前空間接頭辞一覧上にない名前空間ノードは、出力された祖先の開始タグに実際に存在しない場合、名前空間ノードを有形利用している開始タグの中でのみ明示される
排他的である正則なXMLという用語は、排他的正則形式であるXMLを指す。排他的XML正則化方法とは、この仕様書によって定義された、与えられたXML文書の部分集合の排他的正則形式を生成するアルゴリズムである。排他的XML正則化という用語は、あるXML文書の部分集合に対して排他的XML正則化方法を適用する処理を指す。
用途
[編集]排他的XML正則化のアプリケーションは正則なXML[XML-C14N]のためのアプリケーションにとてもよく似ている。しかしながら排他的正則化、すなわちほとんどのXMLコンテキストを除外することと同義の方法は、多くの手続き型アプリケーションによくある多少の変化によって、署名されたXMLのXMLコンテキストが変わる可能性があるという場合に、署名アプリケーションのために不可欠である。
XMLデジタル署名[XML-DSig]のSignedInfo要素について、些細な物理的形式の変化とXMLコンテキストの変化から署名を保護することを可能にする手法は、特殊な正則化方法の仕様のみであることに留意せよ。
制限
[編集]排他的XML正則化は、以下のような二つの追加制限を正則なXML[XML-C14N]の制限に付加させる。
- 正則化されるXMLは、祖先ノードのxml:lang、xml:space、xml:baseのようなXML名前空間の属性の影響を受けるかもしれない。エンベロープされた文書部分集合の中にそれらの属性を受け入れないことに起因する問題を回避するために、正則化されるXML文書部分集合の頂点ノード中にそれらが明確に与えられねばならない。さもなくば、それらが解釈されるXML文書部分集合中のどのコンテキストにも、等価な値を常に宣言されねばならない。
- 正則化されたXMLを利用するアプリケーションは、結合済み名前空間接頭辞が有形利用でないという点でXML名前空間宣言の影響を受けるかもしれない。例としては、値がXPath式であったり、式の評価がその式の中で参照された名前空間接頭辞に影響する属性であろう。あるいは、ある属性値がいくつかのアプリケーションによって有修飾名(QName)[XML-NS]とみなされていたかもしれないが、それは次のようなXPath文字列値であろう。
<number xsi:type="xsd:decimal">10.09</number>
そのような名前空間宣言の問題を回避するために、- XMLは、関連する名前空間接頭辞を有形利用するように修正されなければならないか、
- 名前空間宣言が、解釈されるXMLのどのコンテキストでも同一値として現れなければならないか、
- そのような名前空間の接頭辞は、包括的名前空間接頭辞一覧に存在しなければならない。
排他的XML正則化の必要性
[編集]いくつかの事例では、とりわけ手続き型アプリケーションでの署名済みXMLのために、文書の一部を正則化する目的でそのXMLコンテキストから実質的に独立した方法が必要である。これは、事前に受け取った異なるメッセージから抽出されたものの一部を、メッセージや配送する要素をさまざまな層でXMLにエンベロープしたり、そのようなエンベロープを剥ぎ取ったり、新たなプロトコルメッセージを構築することが、手続き型アプリケーションでは良くあることだからである。論点になっているXMLの一部が署名される場合、これらの処理で署名が破壊されず、署名が実質的に通用可能であることと同様の安全性を提供しつづけるような正則化法が必要である。
簡易な例
[編集]XMLコンテキストの変化が署名にもたらし得るある種の問題の単純例として、以下のような文書が考えられる。即ち、
<n1:elem1 xmlns:n1="http://b.example">
content
</n1:elem1>
この文書が、以下のように他の文書の中にエンベロープされる。
<n0:pdu xmlns:n0="http://a.example">
<n1:elem1 xmlns:n1="http://b.example">
content
</n1:elem1>
</n0:pdu>
前述の最初の文書は正則形式である。しかし、後者の事例のように文書がエンベロープされたと仮定すると、頂点ノードとしてelem1を持つ文書の一部は、次のようなXPath式で後者から抽出することができる。
(//. | //@* | //namespace::*)[ancestor-or-self::n1:elem1]
正則なXMLを適用して得られたXPathノード集合の結果は以下のようになる(この文書に適合する行の折り返しを除く)。
<n1:elem1 xmlns:n0="http://a.example"
xmlns:n1="http://b.example">
content
</n1:elem1>
名前空間n0が正則なXMLによって取り込まれていることに留意せよ。なぜなら、正則なXMLは名前空間コンテキストを取り込むからである。これは、当初のelem1に基づく署名を破壊するような変化である。
再エンベロープに伴う一般的な問題
[編集]文書の一部をエンベロープしたコンテキストが変化する時に起こりうる正則形式のより完全な例として、次のような文書が考えられる。すなわち、
<n0:local xmlns:n0="foo:bar"
xmlns:n3="ftp://example.org">
<n1:elem2 xmlns:n1="http://example.net"
xml:lang="en">
<n3:stuff xmlns:n3="ftp://example.org"/>
</n1:elem2>
</n0:local>
そして、次のようにelem2をエンベロープして変更された。
<n2:pdu xmlns:n1="http://example.com"
xmlns:n2="http://foo.example"
xml:lang="fr"
xml:space="preserve">
<n1:elem2 xmlns:n1="http://example.net"
xml:lang="en">
<n3:stuff xmlns:n3="ftp://example.org"/>
</n1:elem2>
</n2:pdu>
どちらの事例からも、次のXPath評価式が適用されたことによってXPathノード集合が与えられると仮定する。
(//. | //@* | //namespace::*)[ancestor-or-self::n1:elem2]
最初の文書から作られたノード集合へ正則なXMLを適用することにより、次のデータが作られる(この文書に適合する行の折り返しを除く)。
<n1:elem2 xmlns:n0="foo:bar"
xmlns:n1="http://example.net"
xmlns:n3="ftp://example.org"
xml:lang="en">
<n3:stuff></n3:stuff>
</n1:elem2>
しかし、elem2が前述のXMLの両方で同じデータ列として表されているものの、後者に正則なXMLを適用した場合のelem2は次のようなものである(この文書に適合する行の折り返しを除く)。すなわち、
<n1:elem2 xmlns:n1="http://example.net"
xmlns:n2="http://foo.example"
xml:lang="en"
xml:space="preserve">
<n3:stuff xmlns:n3="ftp://example.org"></n3:stuff>
</n1:elem2>
コンテキストの変化が、包括的である正則なXML[XML-C14N]によって直列化されることにより文書の一部に色々な変化をもたらしたことに留意せよ。前者ではn0がコンテキストに取り込まれ、単独で存在しているn3名前空間宣言が正則形式の頂点に押し上げられた。後者ではn0がなくなり、n2が現れ、n3はそのままで、xml:space宣言が現れるのでコンテキストが変化する。ただし、全てのコンテキスト変化が起こるわけではない。後者では、elem2ノードで宣言が存在するために、祖先ノードのxml:langと接頭辞n1の名前空間宣言が存在しない。
他方、ここで仕様を定める排他的XML正則化を用いれば、前述のXPath評価式によって抽出されたelem2の物理的形式は、(この文書に適合する行の折り返しを除き)両方とも次のようになる。すなわち、
<n1:elem2 xmlns:n1="http://example.net"
xml:lang="en">
<n3:stuff xmlns:n3="ftp://example.org"></n3:stuff>
</n1:elem2>
排他的XML正則化の仕様
[編集]排他的XML正則化のデータモデル、処理、入力値、出力データは、次に挙げる例外事項を別にすれば、正則なXML[XML-C14N]と同様である。すなわち、
- 文書部分集合へ正則なXMLを適用する場合、xml:langやxml:spaceのようなXML名前空間の属性を各孤児要素ノードの祖先ノードから検索することを求められた。これらの属性は、同じ属性の宣言がすでに要素のattribute軸に存在する場合を除いて、(それが文書部分集合内に含まれようがそうでなかろうが)要素ノード内に複製された。この検索と複製は、排他的XML正則化法から排除される
- 排他的XML正則化法では、名前空間接頭辞の一覧と既定名前空間の存在を示すトークンの両方、あるいはいずれか一方を含む包括的名前空間接頭辞一覧追加パラメータ(なくても良い)を受け取ってもよい。一覧に存在する全ての名前空間ノードは、正則なXML[XML-C14N]で定められているように扱われる
- 包括的名前空間接頭辞一覧(空値でなく、接頭辞がヌルである既定名前空間を含む)に存在しない接頭辞の名前空間ノードNは、次の条件が全て満たされるなら表示される。すなわち、
- Nの親要素がノード集合に存在し、
- かつ、Nがその親要素で有形利用され
- かつ、その接頭辞が出力された祖先に未だ表示されていない、またはその有形利用している親要素に最も近い出力された祖先がノード集合内にNと同じ名前空間接頭辞と値を持つ名前空間ノードを持たない
- 包括的名前空間接頭辞一覧に既定名前空間の存在をしめすトークンが存在しない場合、xmlns=""を表示する規則が次のよう変更される。ノード集合内にある要素Eのnamespace軸の正則化をする時、次の条件が全て満たされる場合に限り、xmlns=""を出力する。すなわち、
- Eが既定名前空間(すなわち、名前空間宣言を持たない)を有形利用する
- かつ、ノード集合内に既定名前空間ノードを持たない
- かつ、既定名前空間を有形利用するEに最も近い出力された親が、ノード集合内に既定名前空間ノードを持つ
制約付き実装(参考)
[編集]下記が多くの単純な事例に対する、排他的XML正則化法の実装方法である。──ある要素とそのnamespace軸のすべてがノード集合に存在する場合、それが整形式であると仮定すると、その要素が部分集合に存在しないならばそのnamespace軸も存在しない。
- ルートから始まる文書準中の(選択済みXPathノード集合の)完全なツリーを再帰的に処理する(出力された頂点ノードへ祖先のxml:名前空間属性を複製する処理は行われない)
- ノードがXPath部分集合に存在しない場合、再帰的にその子要素ノードの処理を継続する
- 要素ノードがXPath部分集合に存在するなら、下記の名前空間ノードを除き、正則なXML勧告に従ってノードを出力せよ。すなわち、
- stateスタックの最上段から、すでに名前空間ノードの親要素の出力された祖先に表示済みの接頭辞とその値の辞書を複製してns_renderedとする。
- 以下の全てを満たす場合に限り、それぞれの名前空間ノードを表示せよ。すなわち、
- 名前空間ノードが直接の親要素、または自身の属性、または包括的名前空間接頭辞一覧にて有形利用している
- かつ、その接頭辞と値がns_renderedに現れない
- 次の全てを満たす場合に限り、xmlns=""を表示せよ。すなわち、
- 既定名前空間が直接の親要素で有形利用している、または包括的名前空間接頭辞一覧にる既定名前空間接頭辞の存在を示すトークンが存在する
- かつ、要素ノードがノード集合内の名前空間ノードに既定名前空間として宣言された値を持っていない
- かつ、既定名前空間接頭辞がns_rendered辞書に存在しない
- ns_rendered辞書に全ての表示済み名前空間ノード(xmlns=""を含む)を挿入し、既存のあらゆる項目を置き換える。stateスタックにns_renderedを積み、再帰する
- 再帰が戻った後、stateスタックを破棄する
XMLセキュリティでの利用
[編集]排他的な正則化は、XMLデジタル署名やXML暗号でCanonicalizationMethodアルゴリズムや変換に用いられる可能性がある。
- Identifier:
- http://www.w3.org/2001/10/xml-exc-c14n#
- http://www.w3.org/2001/10/xml-exc-c14n#WithComments
正則なXML[XML-C14N]では、一つのXML注釈の直列化を取り込むための"#WighComments"パラメータを使ってよい。このアルゴリズムも、PrefixList属性を持った空のInclusiveNamespaces要素を追加のパラメータとして取る。このヌルかもしれない属性の値は、正則なXML[XML-C14N]で取り扱われる、空白で区切られた名前空間接頭辞と既定名前空間を指す#defaultの一覧である。一覧は、DTDによってCDATA形式としてあるか、XMLスキーマによってxsd:string形式であるとされる。例えば、
<ds:Transform
Algorithm="http://www.w3.org/2001/10/xml-exc-c14n#">
<ec:InclusiveNamespaces PrefixList="dsig soap #default"
xmlns:ec="http://www.w3.org/2001/10/xml-exc-c14n#"/>
</ds:Transform>
上記が排他的正則化の変形を示すが、接頭辞"dsig"または"soap"の名前空間と既定名前空間は、正則なXML[XML-C14N]にしたがって処理されるべきである。
Schema Definition:
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE schema
PUBLIC "-//W3C//DTD XMLSchema 200102//EN" "http://www.w3.org/2001/XMLSchema.dtd"
[
<!ATTLIST schema
xmlns:ec CDATA #FIXED 'http://www.w3.org/2001/10/xml-exc-c14n#'>
<!ENTITY ec 'http://www.w3.org/2001/10/xml-exc-c14n#'>
<!ENTITY % p ''>
<!ENTITY % s ''>
]>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:ec="http://www.w3.org/2001/10/xml-exc-c14n#"
targetNamespace="http://www.w3.org/2001/10/xml-exc-c14n#"
version="0.1" elementFormDefault="qualified">
<xsd:element name="InclusiveNamespaces"
type="ec:InclusiveNamespaces"/>
<xsd:complexType name="InclusiveNamespaces">
<xsd:attribute name="PrefixList" type="xsd:string"/>
</xsd:complexType>
</xsd:schema>
DTD:
<!ELEMENT InclusiveNamespaces EMPTY >
<!ATTLIST InclusiveNamespaces
PrefixList CDATA #REQUIRED >
セキュリティ上の配慮
[編集]この仕様書は、この仕様書と正則なXML[XML-C14N]で与えられたある条件の下で、XPathノード集合を直列化するために用いられる。下記の三つの例を含む。すなわち、
- この仕様書と正則なXML[XML-C14N]の実装では、XML宣言を表示しない
- この仕様書の実装でのみ、"XML"名前空間の属性(例えば、xml:lang、xml:space、xml:base)が直列化される文書の一部に存在するとき、"XML"名前空間の属性を表示しない
- この仕様書の実装では、有形利用する予定の属性値の中に現れる名前空間接頭辞を考慮しない
そのような選択が他のXML仕様書との一貫性を持ち、ワーキンググループのアプリケーション要件を満たす上、XMLアプリケーションがそのアプリケーションコンテクストで有意義かつ一義的であるようなXMLの変形を慎重に構築するために重要である。この説に加えて、この仕様書の制限節と、正則なXML[XML-C14N]の決議節と、XMLデジタル署名[XML-DSig]のセキュリティの考慮節は、入念に注目されるべきである。
対象となるコンテクスト
[編集]この仕様書の要件は、"正則化済みの文書の一部から実際に用いる範囲へ祖先のコンテクストを排除する方法を求める"アプリケーションを満足させるためにある。
ある文書の一部が元の事例から取り出されたと仮定して、この仕様書では、文書の一部から利用されない祖先のあらゆるコンテクストを排除することによってこの要求を満たす。必然的に、その文書の一部を用いた署名[XML-DSig]は、元のコンテクストで妥当性を保ち、元のコンテクストから取り出され、対象となる新たなコンテクストでも等しいだろう。しかし、この仕様書は対象となるコンテクスト内での混同した解釈に反して文書の一部を分離しない。
例えば、要素<Foo/>が元の事例<Bar><Foo/></Bar>で署名されており、そして取り出され、対象の事例<Baz xmlns="http://example.org/bar"><Foo/></Baz>に収められる場合、署名は妥当性を保ったままだが、もしも<Foo/>が名前空間http://example.org/barに属しているように解されたなら、妥当とならないので、ノードがどのように処理されるかに依存する。
この仕様書では、ノード集合の削除(removing)、挿入(inserting)、"整理"(fixing up)の機構を定義しない(この仕様書のような例は、XInclude[XInclude]が稼動する時の結果情報セットの作成(第4.5節)の処理要件を参照せよ)。その代わりに、アプリケーションはXML(すなわち、原本、文書の一部、対象)を慎重に規定しなければならないか、既定名前空間(例えばxmlns="")とXML属性(例えばxml:lang、xml:space、xml:base)を考慮したノード集合の処理(すなわち、削除、置換、挿入など)を入念に定義しなければならない。
「複雑な」ノード集合
[編集]単一の属性ノードを直列化するためにこの仕様書か正則なXML[XML-C14N]を用いる可能性のあるアプリケーションについて検討する。どちらの仕様書の実装も、単一の属性ノードのために名前空間宣言を発行しないだろう。その結果、"慎重に構築された"変形では、直列化のために属性と適切な名前空間宣言を含むノード集合を作成する必要がある。
この例では、整形式XML[XML]が安定したXML[XML-Fragment]となってしまうので、"アプリケーションコンテクストの中で有意義かつ一義的になる"結果を作成することがますます困難になるという警告を与える。
参考文献
[編集]- Keywords
- RFC利用において必要なレベルを示すキーワード
- RFC 2119. Key words for use in RFCs to Indicate Requirement Levels. S. Bradner. Best Current Practice, March 1997.
- http://www.ietf.org/rfc/rfc2119.txtで入手可能
- URI
- 統一資源識別子
- RFC 2396. Uniform Resource Identifiers (URI): Generic Syntax. T. Berners-Lee, R. Fielding, and L. Masinter. Standards Track, August 1998.
- http://www.ietf.org/rfc/rfc2396.txtで入手可能
- XML
- 拡張可能なマーク付け言語 1.0
- Extensible Markup Language (XML) 1.0 (Second Edition). T. Bray, E. Maler, J. Paoli, and C. M. Sperberg-McQueen. W3C Recommendation, October 2000.
- http://www.w3.org/TR/REC-xmlで入手可能
- XML-C14N
- 正則なXML
- Canonical XML J. Boyer. W3C Recommendation, March 2001.
- http://www.w3.org/TR/2001/REC-xml-c14n-20010315で入手可能
- http://www.ietf.org/rfc/rfc3076.txtで入手可能
- XML-DSig
- XML署名 文法と処理方法
- XML-Signature Syntax and Processing. D. Eastlake, J. Reagle, and D. Solo. IETF Draft Standard/W3C Recommendation, August 2001.
- http://www.w3.org/TR/2002/REC-xmldsig-core-20020212/で入手可能
- XML-Fragment
- XMLの断片
- XML Fragment Interchange. P. Grosso, and D. Veillard. W3C Candidate Recommendation, February 2001.
- http://www.w3.org/TR/2001/CR-xml-fragment-20010212で入手可能
- XInclude
- XMLの挿入
- XML Inclusions (XInclude) Version 1.0. J. Marsh, and D. Orchad. W3C Candidate Recommendation, February 2002.
- http://www.w3.org/TR/2002/CR-xinclude-20020221/で入手可能
- XML-NS
- XML名前空間
- Namespaces in XML. T. Bray, D. Hollander, and A. Layman. W3C Recommendation, January 1999.
- http://www.w3.org/TR/1999/REC-xml-names-19990114/で入手可能
- XML-Enc
- XML暗号 文法と処理
- XML Encryption Syntax and Processing. D. Eastlake, and J. Reagle. W3C Candidate Recommendation, March 2002.
- http://www.w3.org/TR/2002/CR-xmlenc-core-20020304/で入手可能
- XML-schema
- XMLスキーマ 第1部 構造
- XML Schema Part 1: Structures D. Beech, M. Maloney, N. Mendelsohn, and H. Thompson. W3C Recommendation, May 2001.
- http://www.w3.org/TR/2001/REC-xmlschema-2-20010502/で入手可能
- XPath
- XMLパス言語
- XML Path Language (XPath) Version 1.0. J. Clark and S. DeRose. W3C Recommendation, November 1999.
- http://www.w3.org/TR/1999/REC-xpath-19991116で入手可能
謝辞(参考)
[編集]後述する人々がこの仕様書の精度を高める貴重なフィードバックを提供した。
- Merlin Hughes, Baltimore
- Thomas Maslen, DSTC
- Paul Denning, MITRE
- Christian Geuer-Pollmann, University Siegen
- Bob Atkinson, Microsoft

{kind=link}